@Collections
-List, Tuple, Dict에 대한 Python Built-in 확장 자료 구조(모듈)
-편의성, 실행 효율 등을 사용자에게 제공
-아래의 모듈이 존재

@deque
-Stack과 Queue를 지원하는 모듈
-List에 비해 효율적인 자료 저장 방식 지원
-deque는 기존 list보다 효율적인 자료구조 제공
->처리 속도 향상


deque 실습)
from collections import deque
deque_list = deque()
for i in range(5):
deque_list.append(i)
print(deque_list)
# deque([0, 1, 2, 3, 4])
deque_list = deque()
for i in range(5):
deque_list.append(i)
print(deque_list) # deque([0, 1, 2, 3, 4])
deque_list.appendleft(10)
print(deque_list) # deque([10, 0, 1, 2, 3, 4])
deque_list = deque()
for i in range(5):
deque_list.append(i)
print(deque_list) # deque([0, 1, 2, 3, 4])
deque_list.rotate(2)
print(deque_list) # deque([3, 4, 0, 1, 2])
deque_list.rotate(2)
print(deque_list) # deque([1, 2, 3, 4, 0])
deque_list = deque()
for i in range(5):
deque_list.append(i)
print(deque_list) # deque([0, 1, 2, 3, 4])
print(deque(reversed(deque_list))) # deque([4, 3, 2, 1, 0])
deque_list = deque()
for i in range(5):
deque_list.append(i)
print(deque_list) # deque([0, 1, 2, 3, 4])
deque_list.extend([5, 6, 7])
print(deque_list) # deque([0, 1, 2, 3, 4, 5, 6, 7])
deque_list = deque()
for i in range(5):
deque_list.append(i)
print(deque_list) # deque([0, 1, 2, 3, 4])
deque_list.extendleft([5, 6, 7])
print(deque_list) # deque([7, 6, 5, 0, 1, 2, 3, 4])
@OrderedDict
-dict와 달리 데이터 입력한 순서대로 dict 반환
(dict 타입은 데이터 저장한 순서대로 출력하지 않음)
->collections의 OrderedDict 사용

-dict 타입 값을 value 또는 key 값으로 정렬할 때 사용 가능

OrderedDict 실습)
from collections import OrderedDict
d = {}
d['x'] = 100
d['y'] = 200
d['z'] = 300
d['l'] = 500
for k, v in d.items():
print(k, v)
# x 100
# y 200
# z 300
# l 500
d = OrderedDict()
d['x'] = 100
d['y'] = 200
d['z'] = 300
d['l'] = 500
for k, v in d.items():
print(k, v)
print("\n")
# x 100
# y 200
# z 300
# l 500
for k, v in OrderedDict(sorted(d.items(), key=lambda t: t[0])).items():
print(k, v)
print("\n")
# l 500
# x 100
# y 200
# z 300
for k, v in OrderedDict(sorted(d.items(),
reverse=True, key=lambda t: t[1])).items():
print(k, v)
# l 500
# z 300
# y 200
# x 100
@defaultdict
-dict 타입 value에 기본 값을 지정, 신규값 생성시 사용

key값이 존재하지 않지만 lambda: 0을 해줌으로서 일단 0출력해줌
(초기값 없을 때 defaultdict 사용하면 편함)
defaultdict 실습)
from collections import defaultdict
from collections import OrderedDict
d = defaultdict(object) # Create a default dictionary
d = defaultdict(lambda: 1) # set Default value 0
print(d["first"]) # 1
text = """Forget Cristiano Ronaldo, Lionel Messi and Robert Lewandowski.
Tottenham's Son Heung-min has delivered a statistical anomaly that sets him out as the deadliest finisher in Europe.
The way Son is performing in comparison to his expected goals is simply remarkable and eclipses all of football's top marksmen since 2016. Not Son.
His consistent ability to score more times than the chances predict, according to the expected goals measure (see green box below), is actually on the rise.
The statistics below, as compiled by understat.com and reported in the Independent, show Son is scoring a jaw-dropping 44 per cent above his xG since August 2016, a period in which he's netted 61 times.
Next on the list is team-mate Harry Kane, who is almost level with Lionel Messi at 21.3 per cent.
Some of the players regarded as the most incisive in front of goal have actually performed worse than their xG, putting Son's measurement on another level. """.lower().split()
print(text) # ['forget', 'cristiano', 'ronaldo,', 'lionel', 'messi', 'and', 'robert', 'lewandowski.', "tottenham's", 'son', 'heung-min', 'has', 'delivered', 'a', 'statistical', 'anomaly', 'that', 'sets', 'him', 'out', 'as', 'the', 'deadliest', 'finisher', 'in', 'europe.', 'the', 'way', 'son', 'is', 'performing', 'in', 'comparison', 'to', 'his', 'expected', 'goals', 'is', 'simply', 'remarkable', 'and', 'eclipses', 'all', 'of', "football's", 'top', 'marksmen', 'since', '2016.', 'not', 'son.', 'his', 'consistent', 'ability', 'to', 'score', 'more', 'times', 'than', 'the', 'chances', 'predict,', 'according', 'to', 'the', 'expected', 'goals', 'measure', '(see', 'green', 'box', 'below),', 'is', 'actually', 'on', 'the', 'rise.', 'the', 'statistics', 'below,', 'as', 'compiled', 'by', 'understat.com', 'and', 'reported', 'in', 'the', 'independent,', 'show', 'son', 'is', 'scoring', 'a', 'jaw-dropping', '44', 'per', 'cent', 'above', 'his', 'xg', 'since', 'august', '2016,', 'a', 'period', 'in', 'which', "he's", 'netted', '61', 'times.', 'next', 'on', 'the', 'list', 'is', 'team-mate', 'harry', 'kane,', 'who', 'is', 'almost', 'level', 'with', 'lionel', 'messi', 'at', '21.3', 'per', 'cent.', 'some', 'of', 'the', 'players', 'regarded', 'as', 'the', 'most', 'incisive', 'in', 'front', 'of', 'goal', 'have', 'actually', 'performed', 'worse', 'than', 'their', 'xg,', 'putting', "son's", 'measurement', 'on', 'another', 'level.']
word_count = {}
for word in text:
if word in word_count.keys():
word_count[word] += 1
else:
word_count[word] = 1
print(word_count) # {'forget': 1, 'cristiano': 1, 'ronaldo,': 1, 'lionel': 2, 'messi': 2, 'and': 3, 'robert': 1, 'lewandowski.': 1, "tottenham's": 1, 'son': 3, 'heung-min': 1, 'has': 1, 'delivered': 1, 'a': 3, 'statistical': 1, 'anomaly': 1, 'that': 1, 'sets': 1, 'him': 1, 'out': 1, 'as': 3, 'the': 10, 'deadliest': 1, 'finisher': 1, 'in': 5, 'europe.': 1, 'way': 1, 'is': 6, 'performing': 1, 'comparison': 1, 'to': 3, 'his': 3, 'expected': 2, 'goals': 2, 'simply': 1, 'remarkable': 1, 'eclipses': 1, 'all': 1, 'of': 3, "football's": 1, 'top': 1, 'marksmen': 1, 'since': 2, '2016.': 1, 'not': 1, 'son.': 1, 'consistent': 1, 'ability': 1, 'score': 1, 'more': 1, 'times': 1, 'than': 2, 'chances': 1, 'predict,': 1, 'according': 1, 'measure': 1, '(see': 1, 'green': 1, 'box': 1, 'below),': 1, 'actually': 2, 'on': 3, 'rise.': 1, 'statistics': 1, 'below,': 1, 'compiled': 1, 'by': 1, 'understat.com': 1, 'reported': 1, 'independent,': 1, 'show': 1, 'scoring': 1, 'jaw-dropping': 1, '44': 1, 'per': 2, 'cent': 1, 'above': 1, 'xg': 1, 'august': 1, '2016,': 1, 'period': 1, 'which': 1, "he's": 1, 'netted': 1, '61': 1, 'times.': 1, 'next': 1, 'list': 1, 'team-mate': 1, 'harry': 1, 'kane,': 1, 'who': 1, 'almost': 1, 'level': 1, 'with': 1, 'at': 1, '21.3': 1, 'cent.': 1, 'some': 1, 'players': 1, 'regarded': 1, 'most': 1, 'incisive': 1, 'front': 1, 'goal': 1, 'have': 1, 'performed': 1, 'worse': 1, 'their': 1, 'xg,': 1, 'putting': 1, "son's": 1, 'measurement': 1, 'another': 1, 'level.': 1}
위 코드는 아래와 같이 쓸 수도 있음
from collections import defaultdict
from collections import OrderedDict
text = """Forget Cristiano Ronaldo, Lionel Messi and Robert Lewandowski.
Tottenham's Son Heung-min has delivered a statistical anomaly that sets him out as the deadliest finisher in Europe.
The way Son is performing in comparison to his expected goals is simply remarkable and eclipses all of football's top marksmen since 2016. Not Son.
His consistent ability to score more times than the chances predict, according to the expected goals measure (see green box below), is actually on the rise.
The statistics below, as compiled by understat.com and reported in the Independent, show Son is scoring a jaw-dropping 44 per cent above his xG since August 2016, a period in which he's netted 61 times.
Next on the list is team-mate Harry Kane, who is almost level with Lionel Messi at 21.3 per cent.
Some of the players regarded as the most incisive in front of goal have actually performed worse than their xG, putting Son's measurement on another level. """.lower().split()
print(text) # ['forget', 'cristiano', 'ronaldo,', 'lionel', 'messi', 'and', 'robert', 'lewandowski.', "tottenham's", 'son', 'heung-min', 'has', 'delivered', 'a', 'statistical', 'anomaly', 'that', 'sets', 'him', 'out', 'as', 'the', 'deadliest', 'finisher', 'in', 'europe.', 'the', 'way', 'son', 'is', 'performing', 'in', 'comparison', 'to', 'his', 'expected', 'goals', 'is', 'simply', 'remarkable', 'and', 'eclipses', 'all', 'of', "football's", 'top', 'marksmen', 'since', '2016.', 'not', 'son.', 'his', 'consistent', 'ability', 'to', 'score', 'more', 'times', 'than', 'the', 'chances', 'predict,', 'according', 'to', 'the', 'expected', 'goals', 'measure', '(see', 'green', 'box', 'below),', 'is', 'actually', 'on', 'the', 'rise.', 'the', 'statistics', 'below,', 'as', 'compiled', 'by', 'understat.com', 'and', 'reported', 'in', 'the', 'independent,', 'show', 'son', 'is', 'scoring', 'a', 'jaw-dropping', '44', 'per', 'cent', 'above', 'his', 'xg', 'since', 'august', '2016,', 'a', 'period', 'in', 'which', "he's", 'netted', '61', 'times.', 'next', 'on', 'the', 'list', 'is', 'team-mate', 'harry', 'kane,', 'who', 'is', 'almost', 'level', 'with', 'lionel', 'messi', 'at', '21.3', 'per', 'cent.', 'some', 'of', 'the', 'players', 'regarded', 'as', 'the', 'most', 'incisive', 'in', 'front', 'of', 'goal', 'have', 'actually', 'performed', 'worse', 'than', 'their', 'xg,', 'putting', "son's", 'measurement', 'on', 'another', 'level.']
word_count = defaultdict(object) # Create Default dictionary
word_count = defaultdict(lambda: 0) # set Default value 0
for word in text:
word_count[word] += 1
for i, v in OrderedDict(sorted(
word_count.items(), key=lambda t: t[1], reverse=True)).items():
print(i, v)
# Output
"""the 10
is 6
in 5
and 3
son 3
a 3
as 3
to 3
his 3
of 3
on 3
lionel 2
messi 2
expected 2
goals 2
since 2
than 2
actually 2
per 2
forget 1
cristiano 1
ronaldo, 1
robert 1
lewandowski. 1
tottenham's 1
heung-min 1
has 1
delivered 1
statistical 1
anomaly 1
that 1
sets 1
him 1
out 1
deadliest 1
finisher 1
europe. 1
way 1
performing 1
comparison 1
simply 1
remarkable 1
eclipses 1
all 1
football's 1
top 1
marksmen 1
2016. 1
not 1
son. 1
consistent 1
ability 1
score 1
more 1
times 1
chances 1
predict, 1
according 1
measure 1
(see 1
green 1
box 1
below), 1
rise. 1
statistics 1
below, 1
compiled 1
by 1
understat.com 1
reported 1
independent, 1
show 1
scoring 1
jaw-dropping 1
44 1
cent 1
above 1
xg 1
august 1
2016, 1
period 1
which 1
he's 1
netted 1
61 1
times. 1
next 1
list 1
team-mate 1
harry 1
kane, 1
who 1
almost 1
level 1
with 1
at 1
21.3 1
cent. 1
some 1
players 1
regarded 1
most 1
incisive 1
front 1
goal 1
have 1
performed 1
worse 1
their 1
xg, 1
putting 1
son's 1
measurement 1
another 1
level. 1"""
@Counter
-Sequence type의 data element들의 개수를 dict 형태로 반환
-text를 row level부터 handling할 때 많이 쓰임
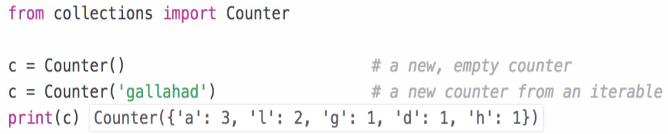
Counter 실습)
from collections import Counter
c = Counter() # a new, empty counter
c = Counter('gallahad') # a new counter from an iterable
print(c) # Counter({'a': 3, 'l': 2, 'g': 1, 'h': 1, 'd': 1})
c = Counter({'red': 4, 'blue': 2}) # a new counter from a mapping
print(c) # Counter({'red': 4, 'blue': 2})
print(list(c.elements())) # ['red', 'red', 'red', 'red', 'blue', 'blue']
c = Counter(cats=4, dogs=8) # a new counter from keyword args
print(c) # Counter({'dogs': 8, 'cats': 4})
print(list(c.elements())) # ['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
c = Counter(a=4, b=2, c=0, d=-2)
d = Counter(a=1, b=2, c=3, d=4)
c.subtract(d) # c- d
print(c) # Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})
c = Counter(a=4, b=2, c=0, d=-2)
d = Counter(a=1, b=2, c=3, d=4)
print(c + d) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2})
print(c & d) # Counter({'b': 2, 'a': 1})
print(c | d) # Counter({'a': 4, 'd': 4, 'c': 3, 'b': 2})
text = """Forget Cristiano Ronaldo, Lionel Messi and Robert Lewandowski.
Tottenham's Son Heung-min has delivered a statistical anomaly that sets him out as the deadliest finisher in Europe.
The way Son is performing in comparison to his expected goals is simply remarkable and eclipses all of football's top marksmen since 2016. Not Son.
His consistent ability to score more times than the chances predict, according to the expected goals measure (see green box below), is actually on the rise.
The statistics below, as compiled by understat.com and reported in the Independent, show Son is scoring a jaw-dropping 44 per cent above his xG since August 2016, a period in which he's netted 61 times.
Next on the list is team-mate Harry Kane, who is almost level with Lionel Messi at 21.3 per cent.
Some of the players regarded as the most incisive in front of goal have actually performed worse than their xG, putting Son's measurement on another level.""".lower().split()
print(Counter(text)) # Counter({'the': 10, 'is': 6, 'in': 5, 'and': 3, 'son': 3, 'a': 3, 'as': 3, 'to': 3, 'his': 3, 'of': 3, 'on': 3, 'lionel': 2, 'messi': 2, 'expected': 2, 'goals': 2, 'since': 2, 'than': 2, 'actually': 2, 'per': 2, 'forget': 1, 'cristiano': 1, 'ronaldo,': 1, 'robert': 1, 'lewandowski.': 1, "tottenham's": 1, 'heung-min': 1, 'has': 1, 'delivered': 1, 'statistical': 1, 'anomaly': 1, 'that': 1, 'sets': 1, 'him': 1, 'out': 1, 'deadliest': 1, 'finisher': 1, 'europe.': 1, 'way': 1, 'performing': 1, 'comparison': 1, 'simply': 1, 'remarkable': 1, 'eclipses': 1, 'all': 1, "football's": 1, 'top': 1, 'marksmen': 1, '2016.': 1, 'not': 1, 'son.': 1, 'consistent': 1, 'ability': 1, 'score': 1, 'more': 1, 'times': 1, 'chances': 1, 'predict,': 1, 'according': 1, 'measure': 1, '(see': 1, 'green': 1, 'box': 1, 'below),': 1, 'rise.': 1, 'statistics': 1, 'below,': 1, 'compiled': 1, 'by': 1, 'understat.com': 1, 'reported': 1, 'independent,': 1, 'show': 1, 'scoring': 1, 'jaw-dropping': 1, '44': 1, 'cent': 1, 'above': 1, 'xg': 1, 'august': 1, '2016,': 1, 'period': 1, 'which': 1, "he's": 1, 'netted': 1, '61': 1, 'times.': 1, 'next': 1, 'list': 1, 'team-mate': 1, 'harry': 1, 'kane,': 1, 'who': 1, 'almost': 1, 'level': 1, 'with': 1, 'at': 1, '21.3': 1, 'cent.': 1, 'some': 1, 'players': 1, 'regarded': 1, 'most': 1, 'incisive': 1, 'front': 1, 'goal': 1, 'have': 1, 'performed': 1, 'worse': 1, 'their': 1, 'xg,': 1, 'putting': 1, "son's": 1, 'measurement': 1, 'another': 1, 'level.': 1})
print(Counter(text)["a"]) # 3
namedtuple 실습)
from collections import namedtuple
# Basic example
Point = namedtuple('Point', ['x', 'y'])
p = Point(11, y=22)
print(p[0] + p[1]) # 33
x, y = p
print(x, y) # 11 22
print(p.x + p.y) # 33
print(Point(x=11, y=22)) # Point(x=11, y=22)
'CS > Python' 카테고리의 다른 글
| News Categorization (0) | 2021.01.18 |
|---|---|
| Linear algebra codes (0) | 2021.01.15 |
| Asterisk (0) | 2021.01.11 |
| Lambda & MapReduce (0) | 2021.01.11 |
| Enumerate & Zip (0) | 2021.01.10 |




