@Selection With Column names
import pandas as pd
import numpy as np
df = pd.read_excel("./data/excel-comp-data.xlsx")
df.head()
@Data selction with index number and column names
-한 개의 column 선택시
df["account"].head(2)0 211829
1 320563
Name: account, dtype: int64
-한 개 이상의 column 선택시
df[["account", "street", "state"]].head(3)
하나의 시리즈나 데이터프레임 데이터를 가져올 때는 2D로 안해주고 str값만 넣어주면 되지만,
여러 개의 컬럼을 가져올 때는 반드시 [ ] 표시를 해줘야 함
@selction with index number
-Column 이름 없이 사용하는 index number은 row 기준 표시
df[:3]
컬럼과 무관하게 row index 기준으로 3줄 가져옴
-Column 이름과 함께 row index 사용시, 해당 column만
df["name"][:3]0 Kerluke, Koepp and Hilpert
1 Walter-Trantow
2 Bashirian, Kunde and Price
Name: name, dtype: object
@Series selection
-시리즈 데이터를 원하는 만큼 불러오기
account_serires = df["account"]
account_serires[:3]0 211829
1 320563
2 648336
Name: account, dtype: int64
-한 개 이상의 인덱스: row 기준으로 인덱스 번호가 1, 5, 2인 것 추출
account_serires[[1,5,2]]1 320563
5 132971
2 648336
Name: account, dtype: int64
-Boolean index
account_serires[account_serires<250000]0 211829
3 109996
4 121213
5 132971
6 145068
7 205217
8 209744
9 212303
10 214098
11 231907
12 242368
Name: account, dtype: int64
@Index 변경
-원래 데이터프레임의 기본 인덱스는 숫자로 되어있음
학번이나 주민번호 등으로 인덱스를 변경하고 싶을 때 사용
df.index = df["account"]
df.head()
-account column이 아직 남아있기 때문에 del 사용해 삭제해줌
del df["account"]
df.head()
@Basic, loc, iloc selection
1) Column과 Index number 사용해 접근
df[["name","street"]][:2]
2) Index name과 Column 사용해 접근
df.loc[[211829,320563],["name","street"]]
3) Column number와 Index number 사용해 접근
(많이 사용되지만 컬럼이 너무 많을 땐 1번 방법 사용)
df[["name", "street"]].iloc[:10]
@Index 재설정(Reindex)
-Merge 없을 때
리스트 값 순서대로 넣어주는 게 가장 편함
df.index = list(range(0,15))
df.head()
@Data Drop
-row 단위로 없애줄 때
Index number로 drop
df.drop(1)
-한 개 이상의 index number로 drop도 가능
df.drop([0, 1, 2, 3])
-axis 축을 기준으로 drop
column 중 "city"
df.drop("city",axis=1).head()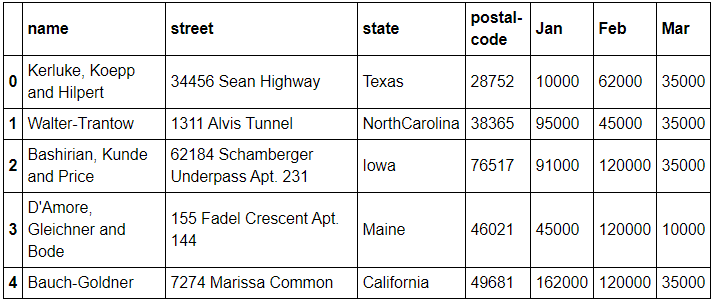
"city"를 drop했으니 데이터프레임에서도 없어졌을 거라 생각하겠지만
데이터프레임에는 여전히 존재
-> Pandas는 원본 데이터를 쉽게 삭제하지 않음
변환된 데이터를 어딘가 복사해 두었다가 그걸 삭제함(원본 데이터가 아닌 복사본의 데이터)
기존의 데이터프레임 자체를 변환하고 싶다면 inplace=True 명령을 따로 해줘야 함
'CS > Python' 카테고리의 다른 글
| 코테 응용하기 좋은 수학 알고리즘 (0) | 2021.03.01 |
|---|---|
| Read & Analysis | 시간복잡도, 공간복잡도 등 (0) | 2021.02.28 |
| Pandas (0) | 2021.02.27 |
| Numpy data i/o (0) | 2021.02.20 |
| Numerical Python - Numpy(3) (0) | 2021.02.20 |



