@Pandas
-구조화된 데이터의 처리를 지원하는 Python 라이브러리
-Python계의 엑셀
-고성능 Array 계산 라이브러리인 Numpy와 통합하여 강력한 스프레드시트 처리 기능 제공
-인덱싱, 연산용 함수, 전처리 함수 등을 제공
@Pandas의 구성
-
Series
-DataFrame 중 하나의 Column에 해당하는 데이터의 모음 Object
(Column 뿐만 아니라 Row도 가져올 수 있음)
Series
list_data = [5, 6, 7, 8, 9]
ex_obj = Series(data = list_data)
print(ex_obj)Series(index = list_name) 이런 식으로 index 이름도 지정 가능

index 값도 핸들링 가능
-data index에 접근
ex_obj["a"]
-data index에 값 할당
ex_obj["a"] = 3.2
ex_obj
-
DataFrame

-Data Table 전체를 포함하는 Object
-DataFrame은 기본적으로 2차원 Matrix 형태라고 가정
-dict 형태로 넣어줄 수도 있지만 잘 안 쓰임
In)
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
# Example from - https://chrisalbon.com/python/pandas_map_values_to_values.html
raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
'age': [42, 52, 36, 24, 73],
'city': ['San Francisco', 'Baltimore', 'Miami', 'Douglas', 'Boston']}
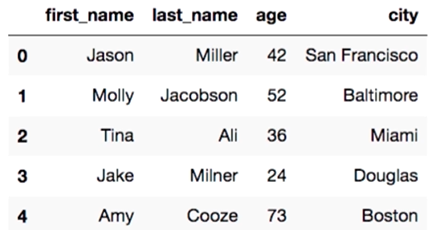
df = pd.DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'city'])
df
Out)
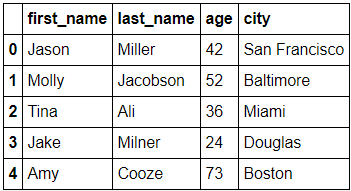
-Column 선택
In)
DataFrame(raw_data, columns = ["age", "city"])
Out)
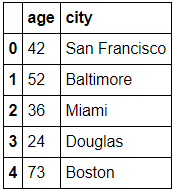
-새로운 Column 추가
In)
DataFrame(raw_data,
columns = ["first_name","last_name","age", "city", "debt"]
)
Out)
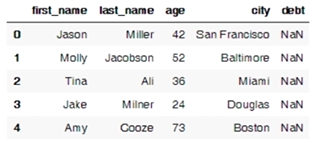
loc: index 이름
iloc: index number
In)
df.loc[1]
Out)
first_name Molly
last_name Jacobson
age 52
city Baltimore
debt NaN
Name: 1, dtype: object
In)
df["age"].iloc[1:]
Out)
1 52
2 36
3 24
4 73
Name: age, dtype: int64
-Column에 새로운 데이터 할당
자주 쓰임
In)
df.age > 40
Out)
0 True
1 True
2 False
3 False
4 True
Name: age, dtype: boolbool 형태로 값 반환
새로운 데이터 할당
In)
df.debt = df.age > 40
df
Out)
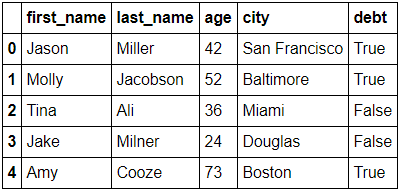
-Transpose
In)
df.T
Out)

-값 출력
In)
df.values
Out)
array([['Jason', 'Miller', 42, 'San Francisco', True, 'M'],
['Molly', 'Jacobson', 52, 'Baltimore', True, 'F'],
['Tina', 'Ali', 36, 'Miami', False, nan],
['Jake', 'Milner', 24, 'Douglas', False, 'F'],
['Amy', 'Cooze', 73, 'Boston', True, nan]], dtype=object)
-csv 변환
In)
df.to_csv()
Out)
',first_name,last_name,age,city,debt,sex\n0,Jason,Miller,42,San Francisco,True,M\n1,Molly,Jacobson,52,Baltimore,True,F\n2,Tina,Ali,36,Miami,False,\n3,Jake,Milner,24,Douglas,False,F\n4,Amy,Cooze,73,Boston,True,\n'
-Column 삭제
In)
del df["debt"]
df
Out)
'CS > Python' 카테고리의 다른 글
| Read & Analysis | 시간복잡도, 공간복잡도 등 (0) | 2021.02.28 |
|---|---|
| Pandas | Selection, index Change, Reindex, Data drop (0) | 2021.02.28 |
| Numpy data i/o (0) | 2021.02.20 |
| Numerical Python - Numpy(3) (0) | 2021.02.20 |
| Numerical Python - Numpy(2) (0) | 2021.02.20 |



