데이터 시각화
-데이터는 수많은 속성과 샘플로 구성되어 한눈에 의미 파악 어려움
-데이터 의미 통찰하고 전달하는 가장 좋은 방법
@getminder 데이터
-5개 대륙, 총 142개 국가에 대한 1952~2007년의 인구 데이터가 5년 간격으로 담겨 있음
-인구 변화 추이는 개별 국가보단 대륙별로 묶어 관찰하는 게 편리
> library(gapminder)
> library(dplyr)
> y <- gapminder %>% group_by(year, continent) %>% summarize(c_pop = sum(pop))
> head(y, 20)
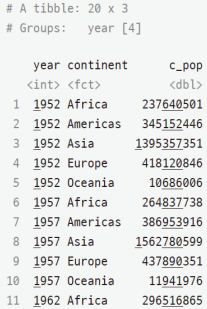
-수치로 요약된 결과를 plot() 이용해 시각화
> plot(y$year, y$c_pop)
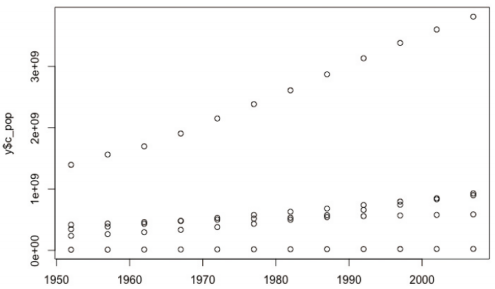
-여러 대륙의 데이터가 하나의 그래프에 표시되므로 추가 옵션 이용해 마커 색이나 모양 서로 다르게 지정
> plot(y$year, y$c_pop, col = y$continent)
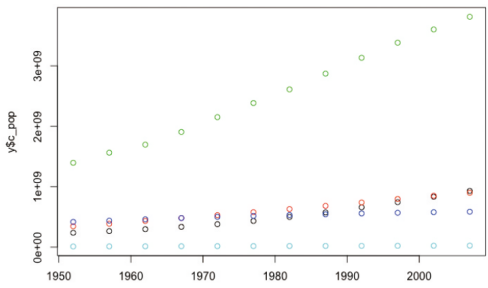
-플롯의 빈 공간에 각 마커를 설명하는 범례 legend를 표시하면 기본적인 시각화가 완성됨
# 범례 개수를 숫자로 지정
> legend("topleft", legend=5, pch=c(1:5), col=c(1:5))
# 범례 개수를 데이터 개수에 맞게 지정
> legend("topleft", legend=levels((y$continent)), pch=c(1:length(levels(y$continent))), col = c(1:length(levels(y$continent))))
시각화의 기본 기능
: 많은 양의 데이터를 효과적으로 관찰
@시각화 효과
-직관 얻을 수 있음
-핵심 명확히 이해할 수 있음
-평균적인 경향과 더불어 이상값도 발견할 수 있음
-데이터에서 문제 빨리 찾아낼 수 있음
gapminder 데이터의 직관적 이해
-원데이터의 속성들을 가능한 그대로 사용해 모든 샘플들을 그래프에 표시하되, 대륙 혹은 국가에 따라 구별된 마커 사용해 gdpPercap, lifeExp, pop 항목의 범위와 특징, 상대적 차이, 대략의 상관관계 확인 가능
> plot(gapminder$gdpPercap, gapminder$lifeExp, col = gapminder$continent)
> lengend("bottomright", legend=levels((gapminder$continent)), pch=c(1:length(levels(gapminder$continent))), col=c(1:length(levels(y$continent))))
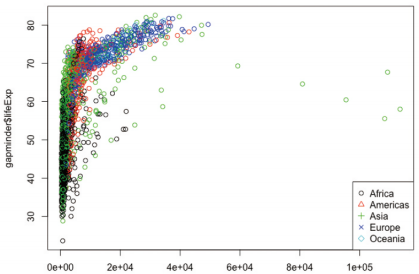
-gdpPercap 값의 전체 범위에 비해 낮은 범위에 샘플들이 몰려 있어 관찰 어려운 경우 로그 스케일 이용해 샘플들 고르게 관찰 가능
> plot(log10(gapminder$gdpPercap), gapminder$lifeExp, col=gapminder$continent)
> lengend("bottomright", legend=levels((gapminder$continent)), pch=c(1:length(levels(gapminder$continent))), col=c(1:length(levels(y$continent))))
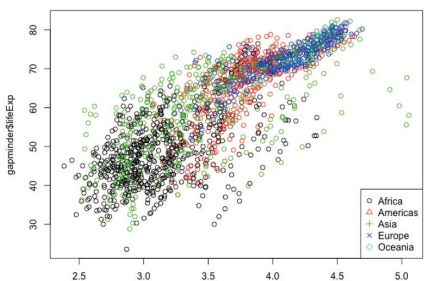
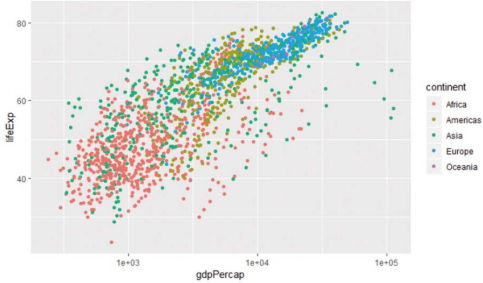
-시각화 전용 라이브러리인 ggplot2 사용하면 그래프의 추가 옵션을 간단히 지정 가능하고 완성도 높은 시각화 결과를 쉽게 얻을 수 있음
> library(ggplot2)
> ggplot(gapminder, aes(x=gdpPercap, y=lifeExp, col=continent)) + geom_point() + scale_x_log10()
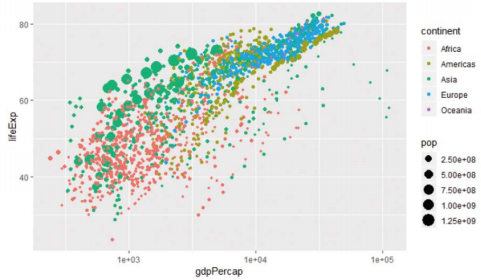
-ggplot() 은 size = pop을 추가함으로써 플롯 마커의 크기가 각 국가의 인구에 비례하도록 지정 가능
> ggplot(gapminder, aes(x=gdpPercap, y=lifeExp, col=continent, size=pop)) + geom_point() + scale_x_log10()
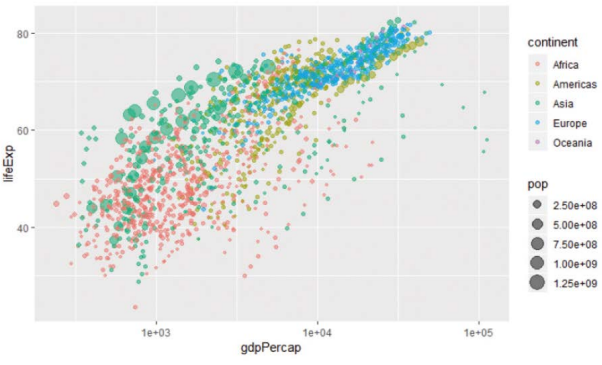
-마커의 투명도 이용한 정보 표시
> ggplot(gapminder, aes(x=gdpPercap, y=lifeExp, col=continent, size=pop)) + geom_point(alpha=0.5) + scale_x_log10()
-데이터를 정교하게 시각화하려면 관측 연도를 구분해 표시하는 것이 더 효과적
-dplyr 라이브러리의 filter() 이용해 각 연도의 데이터를 차례로 추출한 후 그래프를 반복해서 그리는 방법도 있지만
ggplot2 에서 제공하는 facet_wrap() 을 이용하면 데이터 가공과 반복을 이용한 프로그래밍을 간단히 대신 가능
>ggplot(gapminder, aes(x=gdpPercap, y=lifeExp, col=continent, size=pop)) + geom_point(alpha=0.5) + scale_x_log10() + facet_wrap(~year)
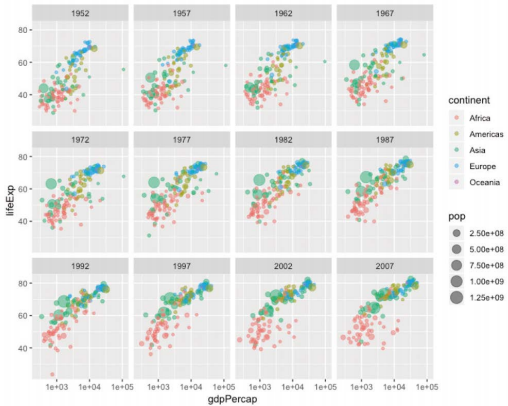
-시각화의 공통 목적 : 데이터에 내재된 의미, 즉 변화, 구성, 분포, 상관관계 등을 명확히 드러내는 것
-데이터를 바라보는 시각화 관점에 변화 주면 데이터에 포함된 여러 의미에 대한 통찰 생김
-다양한 시각화 방법은 데이터 과학의 핵심 기술
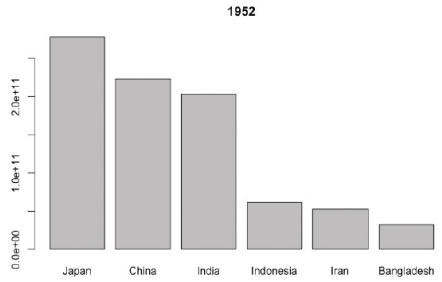
@비교, 순위
-1952년 아시아 대륙 인구 분포에서 각 국가 순위 매기기
> gapminder %>% filter(year==1952&continent=="Asia")%>%ggplot(aes(reorder(country, pop), pop)) + geom_bar(stat="identity") + coord_filp()
# 가로 축에 표시될 때 국가명이 서로 겹치는 문제 해결위해 coord_filp() 사용, 가로축과 세로축 위치 변경
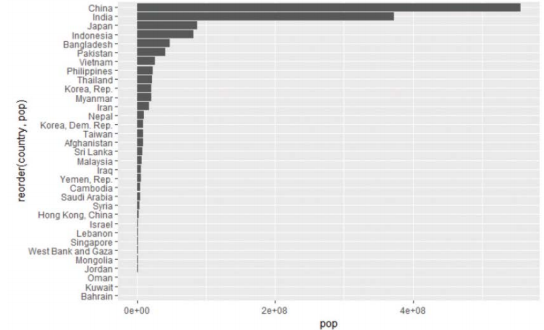
-로그 스케일 축 사용하면 큰 값은 작게, 작은 값은 상대적으로 크게 변환되므로 하나의 그래프에서도 전체적 비교 가능
> gapminder %>% filter(year==1952&continent=="Asia")%>%ggplot(aes(reorder(country, pop), pop)) + geom_bar(stat="identity") scale_y_log10() + coord_filp()
@변화 추세
-gapminder 데이터에 포함된 한국의 lifeExp 변화를 연도에 따라 시각화
-관측 시점의 데이터 값과 관측 기간 동안의 변화를 모두 보여주기 위해 점과 선 이용한 플롯 사용
> gapminder %>% filter(country=="Korea, Rep.") %>% ggplot(aes(year, lifeExp, col=country)) + geom_point() + geom_line()
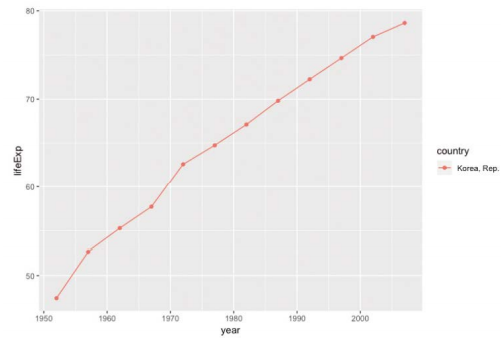
-여러 데이터의 변화를 동시에 비교할 때는 색상으로 구분된 다중 플롯 사용
-ggplot의 geom_smooth() 이용해 평균적인 추세선 표시도 가능
>gapminder %>% ggplot(aes(x=year, y=lifeExp, col=continent)) + geom_point(alpha=0.2) + geom_smooth()
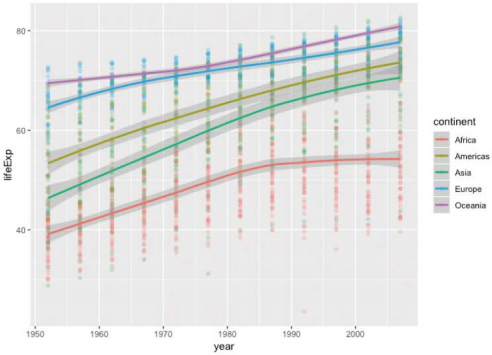
@분포 혹은 구성 비율
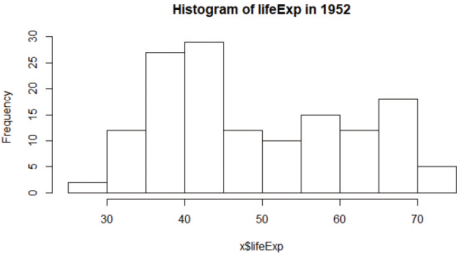
-1952년 전 세계 lifeExp 분포 시각화
-hist()
> x = filter(gapminder, year == 1952)
> hist(x$lifeExp, main="Histogram of lifeExp in 1952")
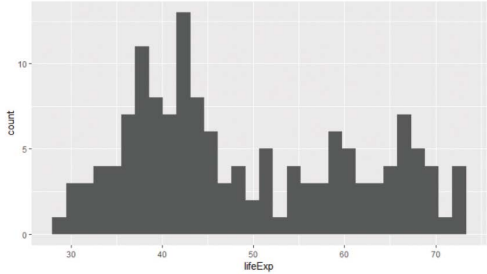
-ggplot()
> x %>% ggplot(aes(lifeExp)) + geom_histogram()
-boxplot() 이용 시 대륙별로 세분화된 분포 특성을 동시에 살펴볼 수 있음
> x %>% ggplot(aes(lifeExp)) + geom_boxplot()
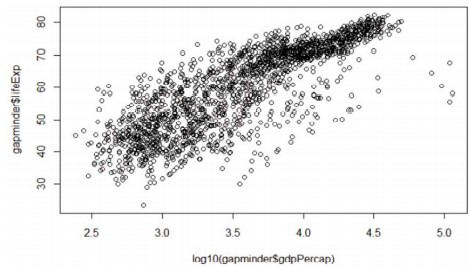
@상관관계
-데이터 분석 과정에서 중요한 작업 중 하나
-데이터에 내재된 의미와 인과관계를 설명하는 단서가 되며, 모델링을 통해 미지의 결과 예측하는 데에도 활용됨
> plot(log10(gapminder$gdpPercap), gapminder$lifeExp)
시각화 도구 : base R
@plot()
-가장 일반적인 그래프 시각화 함수로 직선, 점 등 여러 형태의 플롯 가능
-베이스 R에 내장된 cars 데이터를 통한 기본 형식과 기법 확인
> head(cars)
> plot(cars, type="p", main = "cars") # p는 점 플롯
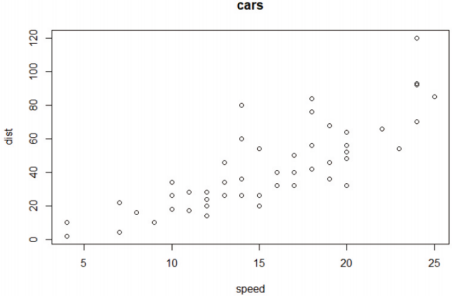
> plot(cars, type="l", main = "cars") # l은 선 사용한 플롯
> plot(cars, type="b", main = "cars") # b는 점과 선 모두 사용한 플롯
> plot(cars, type="h", main = "cars") # h는 히스토그램과 같은 막대그래프
@pie, barplot()
-구성 비율, 순위 등을 시각적으로 확인할 때 유용
> x = gapminder %>% filter(year==1952&continent=="Asia") %>% mutate(gdpPercap*pop) %>% select(country, gdp) %>% arrange(desc(gdp)) %>% head() # mutate() : 기존 값 유지하면서 새로운 변수 추가
> pie(x$gdp, x$country)
> barplot(x$gdp, names.arg=x$country)
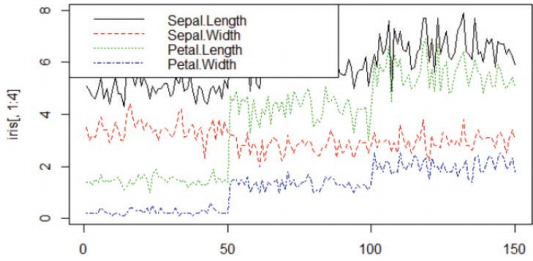
@matplot()
-벡터나 행렬 데이터 이용해 다중 플롯을 빠르게 구현하는데 유용
> matplot(iris[, 1:4], type="l")
> legend("topleft", names(iris)[1:4], lty=c(1, 2, 3, 4), col=c(1, 2, 3, 4))
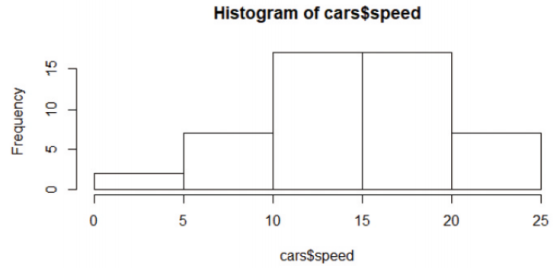
@hist()
-데이터의 분포 히스토그램 표시해주는 함수
-모델링 과정에서 학습데이터의 균형 확인할 때도 사용
> hist(cars$speed)
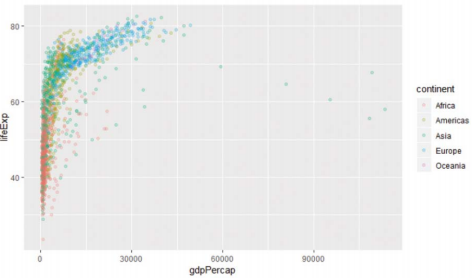
ggplot2 라이브러리
-gg(grammar of graphics)
-가장 많이 사용되는 시각화 라이브러리
@기본 표현식
-세 가지 요소로 구성
> ggplot(gapminder, aes(x=gdpPercap, y=lifeExp, col=continent)) + geom_point(alpha=0.2)
-시각화 객체 생성하는 역할
초기화 과정에서 입력 데이터와 가로축과 세로축에 대응될 항목 지정해야 함
내부에 aes 이용해 지정
(aes 내부에 col이나 size 옵션 활용해 플롯의 생상이나 마커 크기 설정)
@geom_point()
-데이터를 점으로 표시
내부에서 alpha 옵션 통해 점의 불투명도(투명 0.0 ~ 불투명 1.0) 설정 가능
@geom_line()
-데이터를 선으로 표시
@geom_bar()
-데이터를 막대그래프로 표시
-별도의 설정 없으면 분포를 자동으로 계산해 geom_histogram과 동일하게 히스토그램 그림
-> 히스토그램 아닌 막대그래프, 즉 aes()에 x, y가 모두 지정된 그래프 그리려면 stat = "identity" 옵션 지정
@geom_histogram()
-히스토그램 전용 플롯 함수
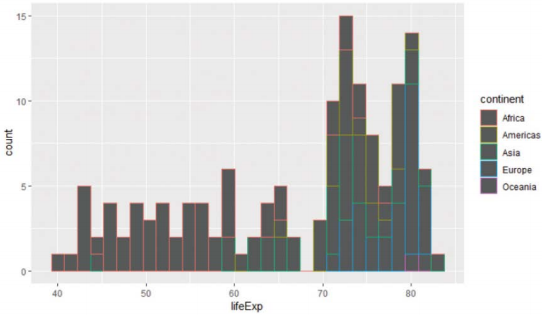
-데이터가 그룹으로 구분되어 있는 경우 기본 옵션은 position = "stack"
> gapminder %>% filter(year==2007) %>% ggplot(aes(lifeExp, col=continent)) + geom_histogram()
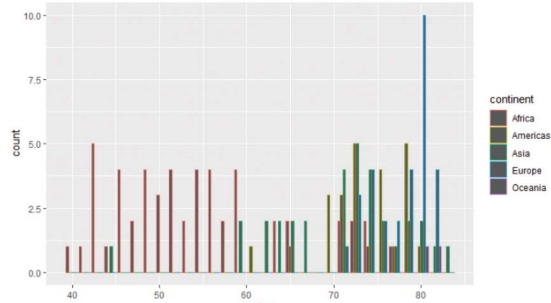
-막대를 나란히 옆으로 표시
-position = "dodge" 옵션 지정
> gapminder %>% filter(year==2007) %>% ggplot(aes(lifeExp, col=continent)) + geom_histogram(position = "dodge")
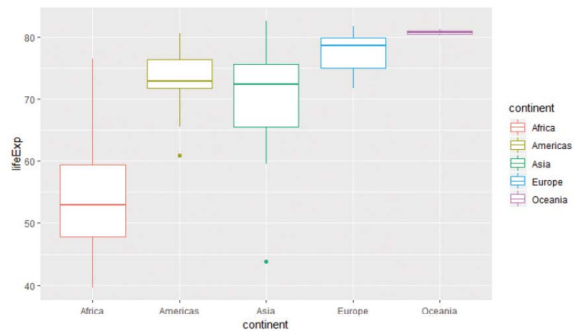
@geom_boxplot()
-여러 항목의 분포를 한꺼번에 관찰
-이상값 파악에 유용
> gapminder %>% filter(year==2007) %>% ggplot(aes(lifeExp, col=continent)) + geom_boxplot()
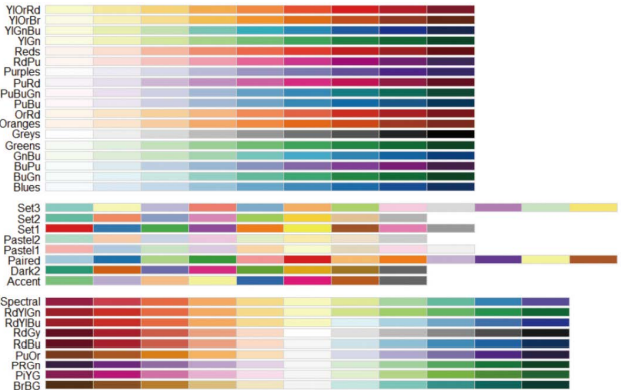
@scale_fill_brewer()
-aes() 내부에 col 옵션 이용 시
사용되는 색은 화면의 색상 구성표인 색상 팔레트에 따라 달라짐
다양한 조합의 색상 팔레트들 중 원하는 것을 선택해 화면 색상 팔레트 변경 가능
RColorBrewer 라이브러기 함께 사용 시 R의 기본 색상 구성보다 다양한 색상 팔레트 중 선택해 사용 가능
> library(RColorBrewer)
> display.brewer.all()
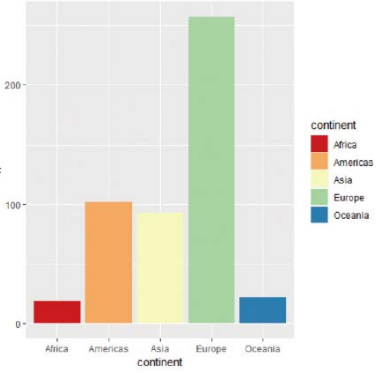
> gapminder %>% filter(lifeExp>70) %>% group_by(year, continent) %>% summarize(n=n_distinct(country)) %>% ggplot(aes(x=continent, y=n)) + geom_bar(stat="identity", aes(fill=continent))+scale_fill_brewer(palette="Spectral")
# Spectral 팔레트를 적용한 그래프
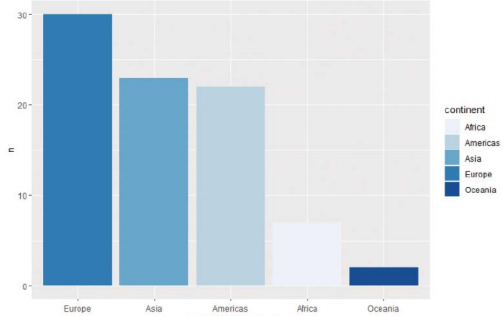
-그래프에 표시되는 데이터 순서 조정 위해 reorder()
> gapminder %>% filter(lifeExp>70) %>% group_by(year, continent) %>% summarize(n=n_distinct(country)) %>% ggplot(aes(x=reorder(continent, -n), y=n)) + geom_bar(stat="identity", aes(fill=continent))+scale_fill_brewer(palette="Blues")
'CS > R | DA' 카테고리의 다른 글
| R 일반화 선형 모델, 회귀, 분류, 결정트리, 랜덤 포레스트 (0) | 2021.06.10 |
|---|---|
| R 모델링, 가설 검정, 예측, 다중 선형 회귀 (0) | 2021.06.09 |
| R 데이터 가공, gapminder 라이브러리, 데이터 정렬 검색, 데이터 프레임 병합 (1) | 2021.04.10 |
| R 파일 입출력, 조건문, 반복문, 사용자 정의 함수, 결측값 처리, 이상값 (0) | 2021.04.08 |
| R read csv, R 데이터형, 벡터, 배열, 데이터프레임, 리스트 (0) | 2021.04.08 |




