@데이터 가공(data wrangling)
-데이터를 보다 효과적으로 분석하기 위해 데이터를 만지고 변형하는 작업
-거의 모든 분야에서 적절한 데이터 가공 필요
(통계 분석, 시각화, 모델링 등)
gapminder 라이브러리
-세계 각국의 기대 수명, 1인당 국내총생산, 인구 데이터 등을 집계해놓은 gapminder 데이터 셋의 일부를 담고 있음
@샘플과 속성의 추출
-각 나라의 기대 수명
> gapminder[, c("country", "lifeExp")]

-행에는 이름이 지정되지 않은 경우가 많아 행 번호를 지정하거나 조건식을 이용하는 것이 일반적
> gapminder[1 : 15, ]

-국가 이름이 "Croatia"인 샘플을 조건식 사용해 추출
> gapminder[gapminder$country == "Croatia", ]

-국가 이름이 "Croatia"인 샘플의 인구(pop) 속성만 조건식 사용해 추출
> gapminder[gapminder$country == "Croatia", "pop"]

-국가 이름이 "Croatia"인 샘플의 인구(pop) 속성과 기대 수명(lifeExp) 속성만 조건식 사용해 추출
> gapminder[gapminder$country == "Croatia", c("lifeExp","pop")]
# 추출할 속성이 여러 개일 경우 c() 이용해 벡터로 묶음

-Croatia의 1990년도 이후의 기대 수명과 인구 추출
> gapminder[gapminder$country=="Croatia"&gapminder$year>1998, c("lifeExp", "pop")]
# 조건식 여러 개를 논리 연산자로 결합

@행, 열 단위 연산
-R에서 제공하는 apply() 이용해 데이터 프레임에 포함된 여러 항목을 한꺼번에 연산 처리
> apply(gapminder[gapminder$country=="Croatia", c("lifeExp", "pop")], 2, mean)

데이터 가공
-데이터 프레임을 중심으로 R이 제공하는 다양한 연산자와 함수를 이용해 이루어지는 작업
-보다 정교하게 추출하려면 조건식 여러 개를 논리 연산자로 결합
-데이터를 탐색하는 과정에서 샘플들의 요약 통계 혹은 행, 열 단위의 빠른 연산이 필요한 때가 있음
-R에서 제공하는 apply() 이용하면 데이터 프레임을 구성하는 여러 항목을 한꺼번에 연산 가능
-base R의 데이터 가공 기법이 인덱스 기반 데이터 접근에 기초하고 있다면 dplyr 라이브러리는 filter 혹은 select 같은 입출력 관계의 함수로 구현함으로써 사용자들이 보다 직관적으로 활용 가능
-따라서 데이터 가공에 특화된 라이브러리를 사용하는 것이 더 효율적
-탐색적 데이터 분석 과정에서 시각화와 데이터 가공은 매우 긴밀하게 연결되어 시각화를 위한 효율적인 가공 기법도 필요
@샘플과 속성 추출
-select() : 열 지정 시 " "없이 열 이름을 그대로 사용할 수 있음
> select(gapminder, country, year, lifeExp)
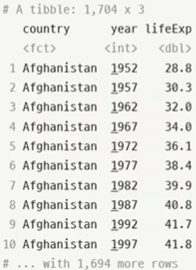
-filter() : 특정 샘플(행) 추출 시 사용
-조건식 구성은 base R과 유사하나 함수 내에서 인덱싱을 위해 데이터 프레임의 이름을 매번 입력하지 않아도 되므로 명형어가 간결
> filter(gapminder, country=="Croatia")
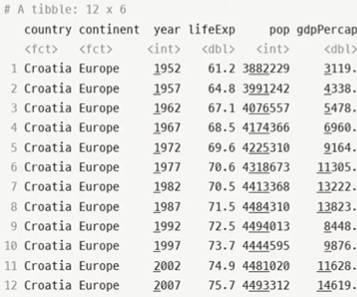
@행, 열 단위의 연산
-group by() : 데이터 프레임에 포함된 factor형 속성을 활용해 전체 데이터를 그룹으로 분류 가능
보통 summarise()를 연이어 사용해 그룹별 통계 지표를 한번에 산출
> summarise(group_by(gapminder, continent, country), pop_avg = mean(pop))

@%>% 연산자를 이용한 연속 처리
일련의 가공 작업 연결
> gapminder %>% group_by(continent, country)%>%summarise(pop_avg=mean(pop))

== > summarise(group_by(gapminder, continent, country), pop_avg = mean(pop))
데이터 정렬과 검색
-정렬과 검색 통해 데이터 자세히 관찰 가능
-arrange()
> arrange(x_avg, desc(V_arg))
뭐 이런 식
-데이터 셋에 중간 통계 값이 포함된 경우도 있으므로 주의 필요
-최댓값의 검색은 max() 사용할 수도 있지만 속성값을 확인할 수 있는 arrange()를 사용하는 게 더 안전
@Date형 데이터 활용
-Date형 속성은 1개월은 31일, 1년은 12개월로 구성되어 일반 숫자형처럼 처리할 경우 데이터 간의 간격이 일정하지 않아 시각화나 모델링 단계에서 잘못 적용될 수 있으므로 특별 처리 필요
-속성 하나에 세 가지 속성(연-월-일) 정보를 포함하는 것이므로 적절히 가공하면 데이터를 보다 세밀하게 분석 가능
데이터 프레임 병합
예) 새로 만들어질 데이터 프레임에서 구분자가 될 year를 key에, 측정값의 속성 이름을 value에 지정하면 gather()은 데이터 프레임을 다음과 같이 재구성
> library(tidyr)
> elec_gen_df = gather(elec_gen, -country, key = "year", value = "ElectricityGeneration")
> elec_use_df = gather(elec_use, -country, key = "year", value = "ElectricityUse")
-재구성된 데이터 프레임을 merge()를 이용해 하나의 데이터 프레임으로 병합
> elec_gen_use = merge(elec_gen_df, elec_use_df)
'CS > R | DA' 카테고리의 다른 글
| R 일반화 선형 모델, 회귀, 분류, 결정트리, 랜덤 포레스트 (0) | 2021.06.10 |
|---|---|
| R 모델링, 가설 검정, 예측, 다중 선형 회귀 (0) | 2021.06.09 |
| R 데이터 시각화, gapminder, 로그스케일, ggplot2 (0) | 2021.04.11 |
| R 파일 입출력, 조건문, 반복문, 사용자 정의 함수, 결측값 처리, 이상값 (0) | 2021.04.08 |
| R read csv, R 데이터형, 벡터, 배열, 데이터프레임, 리스트 (0) | 2021.04.08 |




