일반화 선형 모델 필요성
@반응 변수가 두 가지 값만 가지는 경우
- 정상 / 환자
- 상품 / 하품
glm()
- R에서 일반화 선형 모델은 glm() 사용
- 이전과 달라진 것은 lm -> glm, family=binomial 옵션 추가
- binomial 옵션 : 반응 변수가 두 가지 값만 가진다고 glm에게 알려주는 역할
- 반응 변수가 0과 1 또는 범주형이어야 함 -> 그대로 적용하면 오류!
# factor() 사용
로지스틱 회귀
- 반응 변수가 두 가지 값만 가지는 경우의 회귀
- 참 / 거짓, 성공 / 실패, 환자 / 정상, 사망 / 생존, 승리 / 패배 등
- 원리 : 설명 변수를 x, 반응 변수를 l로 표기

예측
- predict()

범주형 (factor 형)
- 순서값(ordinal value)과 명칭값(nominal value)으로 구분
- 순서값은 거리 개념 있음 -> 숫자 부여하면 모델링에 그대로 참여 가능
과잉 | 과소 적합
@과잉적합(overfitting) : 모델이 훈련 데이터에 과도하게 적응해 일반화 능력 상실하는 현상
@과소적합(underfitting) : 모델이 너무 단순해 데이터의 내재된 구조 학습하지 못할 때 발생

@분류
- 반응 변수가 몇 개의 값만 가지는 경우
예) 1(환자)와 0(정상인) 또는 2(환자), 1(관찰 대상), 0(정상)
회귀(regression) | 분류(classification)
@회귀 : 반응 변수가 연속값 가짐
@분류 : 반응 변수가 이산값 가짐

분류 문제를 푸는 모델
- 결정 트리, 랜덤 포레스트, k-NN, SVM, 신경망, 딥러닝 등
결정 트리
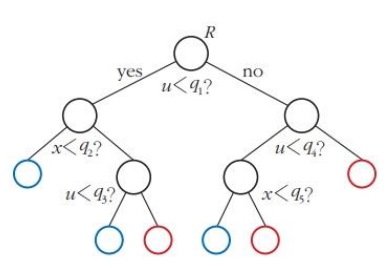
- 결정 트리는 이진 트리
- 특징 공간을 수평 선분과 수직 선분으로 분할해 분류 수행함
결정 트리 시각화

결정 트리 장점과 단점
@단점 : 성능 낮음
@장점
: 해석 가능성interpretability
예측이 빠름
앙상블 기법 사용하면 높은 성능 (랜덤 포리스트)
결측값 처리 가능
범주형 변수 그대로 사용 가능
랜덤 포레스트

- 여러 개의 결정 트리 결합해 성능 향상하는 앙상블ensemble 기법
- 각각의 분류기(결정 트리)를 요소 분류기component classifier라 부름
랜덤 포리스트 내부 살펴보는 함수
- varUsed : 설명 변수가 질문에 사용된 횟수 알려줌
- varImpPlot : 설명 변수의 중요도 그려줌
- treesize : 결정 트리 각각의 리프 노드 개수 알려줌
하이퍼 매개변수 hyper parameter
- 모델 구조나 학습 방법 제어하는 데 사용하는 변수
- 랜덤 포리스트 하이퍼 매개변수
• ntree: 결정 트리 개수 (기본값은 500)
• nodesize: 리프 노드에 도달한 샘플의 최소 개수 (크게 설정할수록 작은 결정 트리)
• maxnodes: 리프 노드 최대 개수
'CS > R | DA' 카테고리의 다른 글
| R 모델링, 가설 검정, 예측, 다중 선형 회귀 (0) | 2021.06.09 |
|---|---|
| R 데이터 시각화, gapminder, 로그스케일, ggplot2 (0) | 2021.04.11 |
| R 데이터 가공, gapminder 라이브러리, 데이터 정렬 검색, 데이터 프레임 병합 (1) | 2021.04.10 |
| R 파일 입출력, 조건문, 반복문, 사용자 정의 함수, 결측값 처리, 이상값 (0) | 2021.04.08 |
| R read csv, R 데이터형, 벡터, 배열, 데이터프레임, 리스트 (0) | 2021.04.08 |




