@탐색적 데이터 분석
-변수 값의 분포, 변수 사이의 상관관계 등을 살펴 데이터 특성 파악
-요약 통계량 계산, 시각화 등
@모델링
-데이터를 가장 잘 설명하는 모델을 찾는 과정
-모델은 변수 사이의 관계를 수학식으로 표현
R
@str()
-데이터의 내용을 요약해 보여주는 함수
@plot()
-시각화 함수
-여러 시각화 옵션
-col : 색깔 지정
xlab, ylab : 축의 이름 지정
pch : 기호 모양 지정

> ?plot 처럼 ? 기호 사용해 도움말 볼 수 있음
iris
> str(iris)
> head(iris, 10) # 내용의 일부 확인(10줄)
> plot(iris)
> plot(iris$Petal.Width, iris$Petal.Length, col=Species)
# 각각 x, y축, 색은 종별로 다르게 지정하라
csv
read.csv() 로 파일 읽기
summary() # 요약 통계 보여줌
@탐색적 데이터 분석의 효능
-전략 수립에 도움
@탐색적 데이터 분석의 한계
-돈을 더 버는 전략을 짤 수는 있어도, 새로운 전략에서 수입이 얼마나 더 늘지 정확히 예측은 불가
@모델링
-예측 가능 -> 미래 재정 포트폴리오 짤 수 있음
데이터 과학 문법
-변수 : 데이터 저장 공간
-데이터형 : 숫자형, 문자형, 범주형, 논리형, 특수 상수 등
-연산자 : 산술, 비교, 논리 연산자
-벡터 : 단일값들의 모임
-배열 : 열과 행을 가지는 데이터 집합. 벡터의 요소들이 다시 벡터로 구성된 형태
-데이터 프레임 : 서로 다른 데이터 형이 표 형태로 정리된 구조. 각 속성의 크기가 같음
-리스트 : 데이터 프레임과 유사한 표 형태의 구조. 각 속성의 크기가 달라도 됨
변수에 값 저장
-=, <-, -> 이용한 값 대입(=보다 <-이 우선 실행)
변수 이름 규칙
-대소문자 구별
-특수문자 쓸 수 없음
-_(밑줄)이나 .(마침표) 기호 쓸 수 있음
-숫자나 밑줄을 변수 첫 글자로 쓸 수 없음
-미리 정해진 명령어인 if, while, for 등의 예약어 사용 불가
-단순한 x, y, z보다는 의미가 드러나는 게 좋음
-한글 이름도 가능하지만 영문 권장
R의 기본 데이터형
| 데이터형 | 종류 |
| 숫자형 | int : 정수, num : 실수, cplx : 복소수 |
| 문자형 | chr : 작은따옴표나 큰따옴표로 묶어 표기 |
| 범주형 | factor : level에 따라 분류된 형태 |
| 논리형 | TRUE(T), FALSE(F) |
| 특수 상수 | NULL : 정의되지 않은 값 NA : 결측값 -Inf 와 Inf(음의 무한대와 양의 무한대) NaN : 0/0, Inf/Inf 등과 같이 연산 불가능한 값 표시 |
데이터형 확인 함수
| 함수 | 설명 |
| class(x) | R 객체지향 관점에서 x의 데이터형 |
| typeof(x) | R 언어 자체 관점에서 x의 데이터형 |
| is.integer(x) | x가 정수형이면 TRUE, 아니면 FALSE |
| is.numeric(x) | x가 실수형이면 TRUE, 아니면 FALSE |
| is.complex(x) | x가 복소수형이면 TRUE, 아니면 FALSE |
| is.character(x) | x가 문자형이면 TRUE, 아니면 FALSE |
| is.na(x) | x가 NA이면 TRUE, 아니면 FALSE |
데이터형 변환 함수
| 함수 | 설명 |
| as.factor(x) | x를 범주형으로 변환 |
| as.integer(x) | x를 정수형으로 변환 |
| as.numeric(x) | x를 숫자형으로 변환 |
| as.character(x) | x를 문자형으로 변환 |
| as.matrix(x) | x를 행렬로 변환 |
| as.array(x) | x를 배열로 변환 |
벡터
-여러 단일값을 하나의 변수명으로 저장 가능
단일 값을 하나의 변수로 저장하면 값이 많은 경우 변수의 수도 증가하게 됨
-> 하나의 벡터 변수로 여러 단일값 저장
@벡터 생성
-벡터 생성 연산자 ':' 이용
> 1 : 7 # 1부터 7까지 1씩 증가시켜 요소가 7개인 벡터 생성
> 7 : 1 # 7부터 1까지 1씩 감소시켜 요소가 7개인 벡터 생성
-vector() 이용
요소의 개수가 n개인 빈 벡터 생성
>vector(length = 5)
-c() 이용
일반 벡터 생성
> c(1 : 5) # 1부터 5까지 1씩 증가시켜 요소가 5개인 벡터 생성
> c(1, 2, 3, c(4 : 6)) # 1부터 3까지 요소와 4부터 6까지 요소를 결합한 1부터 6까지 요소로 구성된 벡터 생성
-seq() 이용
순열 벡터 생성
> seq(from=1, to=10, by=2) # 1부터 10까지 2씩 증가하는 벡터 생성
> seq(0, 1, by=0.1) # 0부터 1까지 0.1씩 증가하는 요소가 11개인 벡터 생성
> seq(0, 1, length.out=11) # 0부터 1까지 요소가 11개인 벡터 생성
-rep() 이용
반복 벡터 생성
> rep(c(1 : 3), times =2) # (1, 2, 3) 벡터를 2번 반복한 벡터 생성
> rep(c(1 : 3), each =2) # (1, 2, 3) 벡터의 개별 요소를 2번 반복한 벡터 생성
@벡터 간 연산
-벡터의 길이가 같거나 요소 개수가 배수 관계에 있을 때 연산 가능
@벡터 연산에 유용한 함수
-all(), any() : 벡터 내 모든, 일부 요소의 조건 검토
-head(), tail() : 데이터의 앞, 뒤 일부 요소 추출(기본 6개 추출)
-union(), intersect(), setdiff(), setequal() : 벡터 간 집합 연산
각각 합집합, 교집합, 차집합, 동일 요소 비교
(setequal()은 TRUE, FALSE로 값 반환)
배열
-열과 행으로 구성된 데이터
@배열 생성 함수
-array() : N차원 배열 생성
> x = array(1 : 5, c(2, 4)) # 1~5 값을 2X4 행렬에 할당
> x

> x[1, ] # 1행 요소 값 출력

> x[, 2] # 2열 요소 값 출력

-matrix() : 2차원 배열 생성
> x = 1 : 12
> x

> matrix(x, nrow=3) # 행렬로 구성할 벡터, 행과 열 수 중 하나 결정

> matrix(x, nrow=3, byrow=T) # byrow : 데이터를 행 단위로 배치할지 여부(T/F)

-cbind(), rbind() : 열, 행 단위로 묶어 배열 생성
> v1 = c(1, 2, 3, 4)
> v2 = c(5, 6, 7, 8)
> v3 = c(9, 10, 11, 12)
> cbind(v1, v2, v3) # 열 단위로 묶어 배열 생성

> rbind(v1, v2, v3) # 행 단위로 묶어 배열 생성

-apply() : 배열의 행 또는 열별로 함수 적용
> x = array(1 : 12, c(3, 4))
> x

> apply(x, 1, mean) # 가운데 값이 1이면 함수를 행별로 적용
[1] 5.5 6.5 7.5
> apply(x, 2, mean) # 가운데 값이 2이면 함수를 열별로 적용
[1] 2 5 8 11
-dim() : 배열의 크기(차원의 수)
> x = array(1 : 12, c(3, 4))
> dim(x)

-sample() : 벡터나 배열에서 샘플 추출
> x = array(1 : 12, c(3, 4))
> sample(x) # 배열 요소를 임의로 섞어 추출

> sample(x, 10) # 배열 요소 중 10개를 골라 추출

> sample(x, 10, prob = c(1 :12)/24) # 각 요소별 추출 확률을 달리할 수 있음

> sample(10) # 단순히 숫자만 사용해 샘플 만들 수 있음

데이터 프레임
-가장 흔히 쓰이는 표 형태의 데이터 구조 가짐
-행렬과 달리 여러 데이터형을 혼합해 저장 가능
-리스트와 달리 행의 수를 일치시켜서 저장해야 함
@데이터 프레임 생성 : data.frame() 이용
> name = c("철수", "춘향", "길동")
> age = c(22, 20, 25)
> gender = factor(c("M", "F", "M"))
> blood.type = factor(c("A", "O", "B"))
> patients = data.frame(name, age, gender, blood.type)
> patients
@데이터 프레임 요소 접근
-$, [, ], 조건식 등을 이용해 접근
> patients$name #name 속성 값 출력

> patients[1, ] # 1행 값 출력

> patients[, 2] # 2열 값 출력

> patients[3, 1] # 3행 1열 값 출력

> patients[patients$name=="철수", ] # 환자 중 철수에 대한 정보 추출

> patients[patients$name=="철수", c("name", "age")] # 철수 이름과 나이 정보만 추출

@데이터 프레임에 유용한 함수
-attach(), detach() : 데이터 프레임의 속성명을 변수명으로 변경
> head(cars) # cars 데이터 셋 확인. head()의 기본 기능은 앞 6개 데이터 추출

> speed

-> speed 변수가 독립적으로 존재하지 않기 때문에 발생
> attach(cars) # attach()를 통해 cars의 각 속성을 변수로 이용하게 함
> speed

> detach(cars) # cars의 각 속성을 변수로 사용하는 것을 해제함
> speed

-with() : 데이터 프레임에 다양한 함수 적용
> mean(cars$speed) # 데이터 속성을 이용해 함수 적용
> with(cars, mean(speed)) # with()를 이용해 함수 적용
-subset() : 데이터 프레임에서 일부 데이터만 추출
# 속도가 20 초과인 데이터만 추출
> subset(cars, speed > 20)
# 속도가 20 초과인 데이터 중 dist를 제외한 데이터만 추출
> subset(cars, speed > 20, select = -c(dist))
-na.omit() : 데이터 프레임의 결측값 제거
> head(airquality) # 이 데이터에는 NA가 포함돼 있음
> head(na.omit(airquality)) # NA 포함된 값 제외하여 추출
-merge() : 여러 데이터 프레임 병합
> name = c("철수", "춘향", "길동")
> age = c(22, 20, 25)
> gender = factor(c("M", "F", "M"))
> blood.type = factor(c("A", "O", "B"))
> patients1 = data.frame(name, age, gender)
> patients1

> patients2 = data.frame(name, blood.type)
> patients2

> patients = merge(patients1, patients2, by = "name")
> patients

리스트
-서로 다른 기본 데이터형을 갖는 자료 구조 포함 가능
-데이터 프레임보다 넓은 의미의 데이터 모임
-데이터 프레임과 달리 모든 속성의 크기가 같을 필요 없음
@리스트 생성 : list()
> patients = data.frame(name = c("철수", "춘향", "길동"), age = c(22, 20, 25), gender = factor(c("M", "F", "M")), blood.type = factor(c("A", "O", "B")))
> no.patients = data.frame(day = c(1 : 6), no = c(50, 60, 55, 52, 65, 58))
# 데이터 단순 추가
> listPatients = list(patients, no.patients)
> listPatients
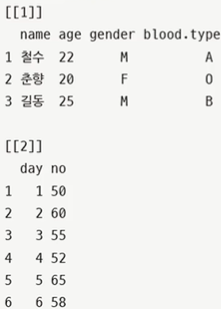
# 각 데이터에 이름 부여하며 추가
> listPatients = list(patients = patients, no.patients = no.patients)
> listPatients

@리스트 요소에 접근 : $, [[ ]]
> listPatients$patients # 요소명 입력

> listPatients[[1]] # 인덱스 입력

> listPatients[["patients"]] # 요소명을 " "에 입력

@리스트에 유용한 함수
-lapply(), sapply() : 리스트 요소에 다양한 함수 적용
# 요소의 평균 구하기
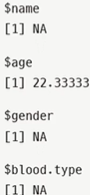
> lapply(listPatients$no.patients, mean)

# patients 요소의 평균 구해줌. 숫자 형태가 아닌 것은 평균 구해지지 않음
> lapply(listPatients$patients, mean)
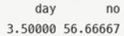
> sapply(listPatients$no.patients, mean)
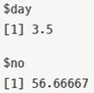
# sapply()의 simplify 옵션을 F로 하면 lapply() 결과와 동일한 결과 반환
> sapply(listPatients$no.patients, mean, simplify = F)
'CS > R | DA' 카테고리의 다른 글
| R 일반화 선형 모델, 회귀, 분류, 결정트리, 랜덤 포레스트 (0) | 2021.06.10 |
|---|---|
| R 모델링, 가설 검정, 예측, 다중 선형 회귀 (0) | 2021.06.09 |
| R 데이터 시각화, gapminder, 로그스케일, ggplot2 (0) | 2021.04.11 |
| R 데이터 가공, gapminder 라이브러리, 데이터 정렬 검색, 데이터 프레임 병합 (1) | 2021.04.10 |
| R 파일 입출력, 조건문, 반복문, 사용자 정의 함수, 결측값 처리, 이상값 (0) | 2021.04.08 |




